
CSV (comma-separated value) files are a common file format for transferring and storing data. The ability to read, manipulate, and write data to and from CSV files using Python is a key skill to master for any data scientist or business analysis. In this post, we’ll go over what CSV files are, how to read CSV files into Pandas DataFrames, and how to write DataFrames back to CSV files post analysis.
Pandas is the most popular data manipulation package in Python, and DataFrames are the Pandas data type for storing tabular 2D data.
Load CSV files to Python Pandas
The basic process of loading data from a CSV file into a Pandas DataFrame (with all going well) is achieved using the “read_csv” function in Pandas:
# Load the Pandas libraries with alias 'pd'
import pandas as pd
# Read data from file 'filename.csv'
# (in the same directory that your python process is based)
# Control delimiters, rows, column names with read_csv (see later)
data = pd.read_csv("filename.csv")
# Preview the first 5 lines of the loaded data
data.head()
While this code seems simple, an understanding of three fundamental concepts is required to fully grasp and debug the operation of the data loading procedure if you run into issues:
- Understanding file extensions and file types – what do the letters CSV actually mean? What’s the difference between a .csv file and a .txt file?
- Understanding how data is represented inside CSV files – if you open a CSV file, what does the data actually look like?
- Understanding the Python path and how to reference a file – what is the absolute and relative path to the file you are loading? What directory are you working in?
- CSV data formats and errors – common errors with the function.
Each of these topics is discussed below, and we finish this tutorial by looking at some more advanced CSV loading mechanisms and giving some broad advantages and disadvantages of the CSV format.
1. File Extensions and File Types
The first step to working with comma-separated-value (CSV) files is understanding the concept of file types and file extensions.
- Data is stored on your computer in individual “files”, or containers, each with a different name.
- Each file contains data of different types – the internals of a Word document is quite different from the internals of an image.
- Computers determine how to read files using the “file extension”, that is the code that follows the dot (“.”) in the filename.
- So, a filename is typically in the form “<random name>.<file extension>”. Examples:
- project1.DOCX – a Microsoft Word file called Project1.
- shanes_file.TXT – a simple text file called shanes_file
- IMG_5673.JPG – An image file called IMG_5673.
- Other well known file types and extensions include: XLSX: Excel, PDF: Portable Document Format, PNG – images, ZIP – compressed file format, GIF – animation, MPEG – video, MP3 – music etc. See a complete list of extensions here.
- A CSV file is a file with a “.csv” file extension, e.g. “data.csv”, “super_information.csv”. The “CSV” in this case lets the computer know that the data contained in the file is in “comma separated value” format, which we’ll discuss below.
File extensions are hidden by default on a lot of operating systems. The first step that any self-respecting engineer, software engineer, or data scientist will do on a new computer is to ensure that file extensions are shown in their Explorer (Windows) or Finder (Mac) windows.
To check if file extensions are showing in your system, create a new text document with Notepad (Windows) or TextEdit (Mac) and save it to a folder of your choice. If you can’t see the “.txt” extension in your folder when you view it, you will have to change your settings.
- In Microsoft Windows: Open Control Panel > Appearance and Personalization. Now, click on Folder Options or File Explorer Option, as it is now called > View tab. In this tab, under Advance Settings, you will see the option Hide extensions for known file types. Uncheck this option and click on Apply and OK.
- In Mac OS: Open Finder > In menu, click Finder > Preferences, Click Advanced, Select the checkbox for “Show all filename extensions”.
2. Data Representation in CSV files
A “CSV” file, that is, a file with a “csv” filetype, is a basic text file. Any text editor such as NotePad on windows or TextEdit on Mac, can open a CSV file and show the contents. Sublime Text is a wonderful and multi-functional text editor option for any platform.
CSV is a standard for storing tabular data in text format, where commas are used to separate the different columns, and newlines (carriage return / press enter) used to separate rows. Typically, the first row in a CSV file contains the names of the columns for the data.
And example table data set and the corresponding CSV-format data is shown in the diagram below.
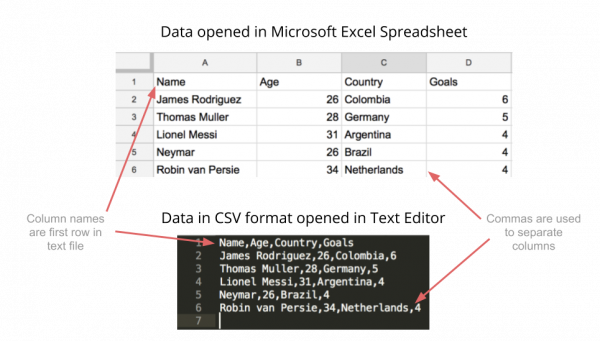
Note that almost any tabular data can be stored in CSV format – the format is popular because of its simplicity and flexibility. You can create a text file in a text editor, save it with a .csv extension, and open that file in Excel or Google Sheets to see the table form.
Other Delimiters / Separators – TSV files
The comma separation scheme is by far the most popular method of storing tabular data in text files.
However, the choice of the ‘,’ comma character to delimiters columns, however, is arbitrary, and can be substituted where needed. Popular alternatives include tab (“\t”) and semi-colon (“;”). Tab-separate files are known as TSV (Tab-Separated Value) files.
When loading data with Pandas, the read_csv function is used for reading any delimited text file, and by changing the delimiter using the sep parameter.
Delimiters in Text Fields – Quotechar
One complication in creating CSV files is if you have commas, semicolons, or tabs actually in one of the text fields that you want to store. In this case, it’s important to use a “quote character” in the CSV file to create these fields.
The quote character can be specified in Pandas.read_csv using the quotechar argument. By default (as with many systems), it’s set as the standard quotation marks (“). Any commas (or other delimiters as demonstrated below) that occur between two quote characters will be ignored as column separators.
In the example shown, a semicolon-delimited file, with quotation marks as a quotechar is loaded into Pandas, and shown in Excel. The use of the quotechar allows the “NickName” column to contain semicolons without being split into more columns.

3. Python – Paths, Folders, Files
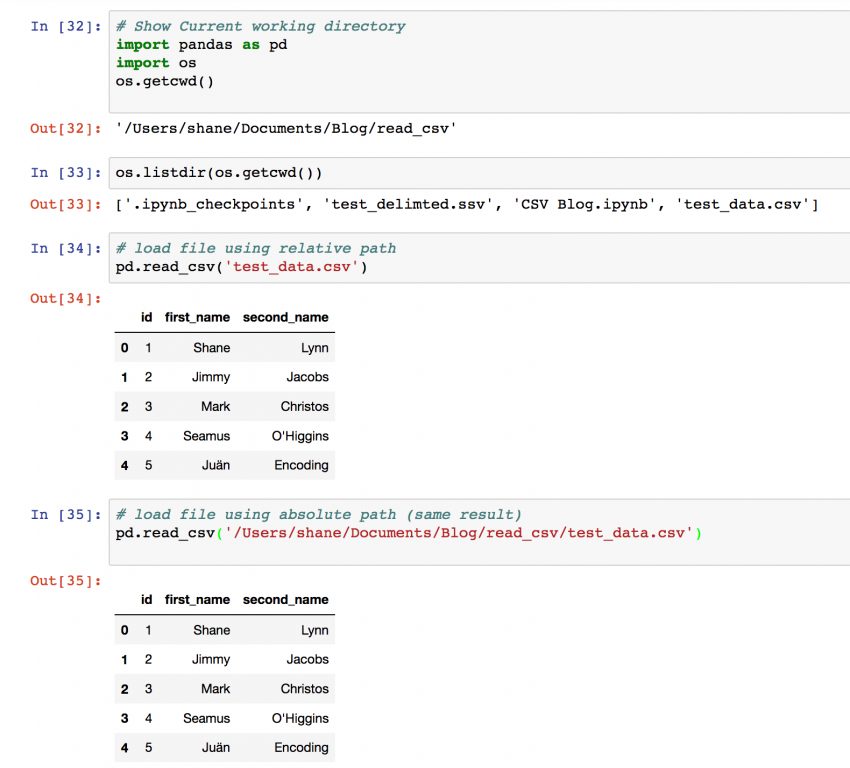
When you specify a filename to Pandas.read_csv, Python will look in your “current working directory“. Your working directory is typically the directory that you started your Python process or Jupyter notebook from.
Finding your Python Path
Your Python path can be displayed using the built-in os module. The OS module is for operating system dependent functionality into Python programs and scripts.
To find your current working directory, the function required is os.getcwd(). The os.listdir() function can be used to display all files in a directory, which is a good check to see if the CSV file you are loading is in the directory as expected.
# Find out your current working directory import os print(os.getcwd()) # Out: /Users/shane/Documents/blog # Display all of the files found in your current working directory print(os.listdir(os.getcwd()) # Out: ['test_delimted.ssv', 'CSV Blog.ipynb', 'test_data.csv']
In the example above, my current working directory is in the ‘/Users/Shane/Document/blog’ directory. Any files that are places in this directory will be immediately available to the Python file open() function or the Pandas read csv function.
Instead of moving the required data files to your working directory, you can also change your current working directory to the directory where the files reside using os.chdir().
File Loading: Absolute and Relative Paths
When specifying file names to the read_csv function, you can supply both absolute or relative file paths.
- A relative path is the path to the file if you start from your current working directory. In relative paths, typically the file will be in a subdirectory of the working directory and the path will not start with a drive specifier, e.g. (data/test_file.csv). The characters ‘..’ are used to move to a parent directory in a relative path.
- An absolute path is the complete path from the base of your file system to the file that you want to load, e.g. c:/Documents/Shane/data/test_file.csv. Absolute paths will start with a drive specifier (c:/ or d:/ in Windows, or ‘/’ in Mac or Linux)
It’s recommended and preferred to use relative paths where possible in applications, because absolute paths are unlikely to work on different computers due to different directory structures.
4. Pandas CSV File Loading Errors
The most common error’s you’ll get while loading data from CSV files into Pandas will be:
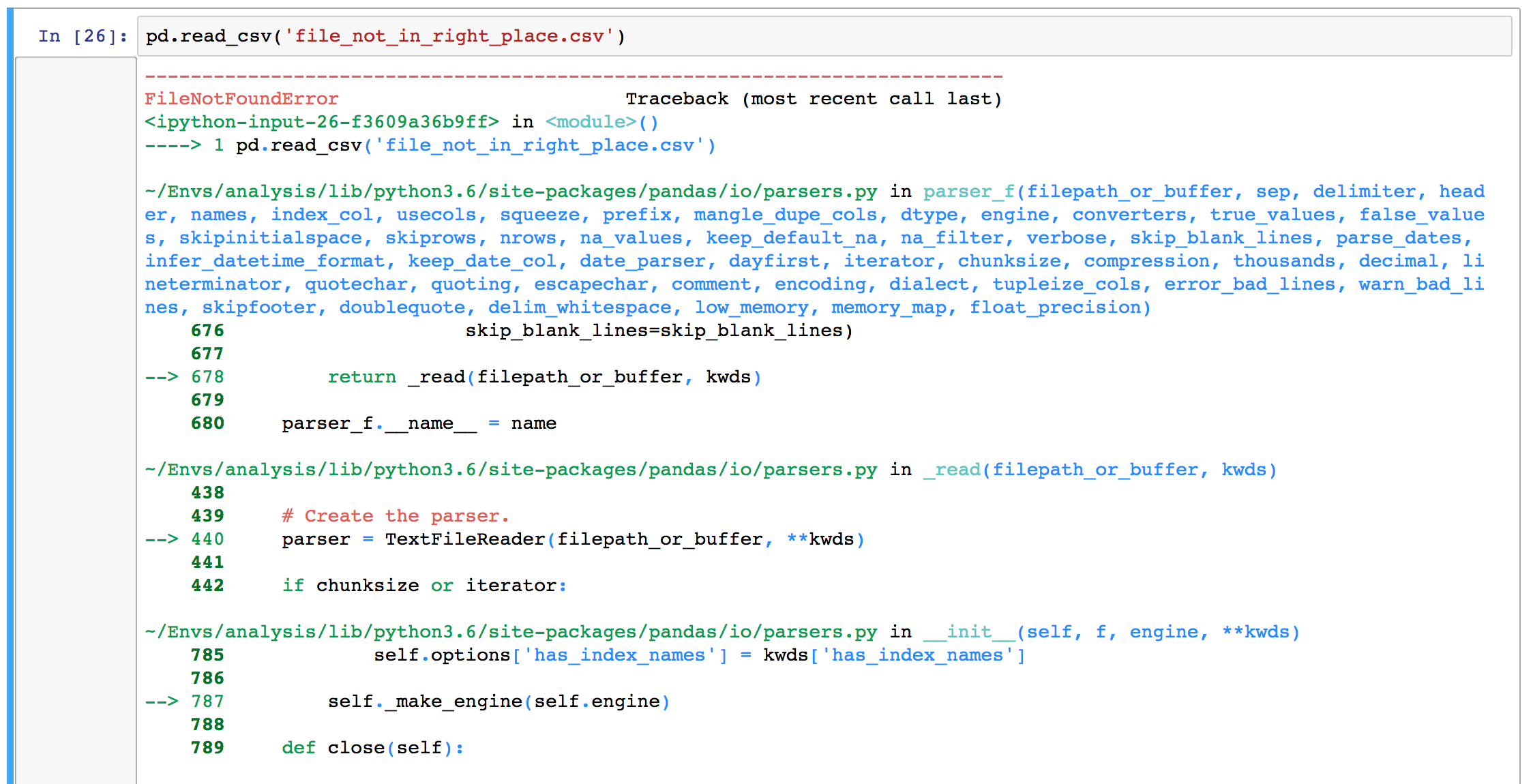
FileNotFoundError: File b'filename.csv' does not exist
A File Not Found error is typically an issue with path setup, current directory, or file name confusion (file extension can play a part here!)UnicodeDecodeError: 'utf-8' codec can't decode byte in position : invalid continuation byte
A Unicode Decode Error is typically caused by not specifying the encoding of the file, and happens when you have a file with non-standard characters. For a quick fix, try opening the file in Sublime Text, and re-saving with encoding ‘UTF-8’.pandas.parser.CParserError: Error tokenizing data.
Parse Errors can be caused in unusual circumstances to do with your data format – try to add the parameter “engine=’python'” to the read_csv function call; this changes the data reading function internally to a slower but more stable method.
Advanced Read CSV Files
There are some additional flexible parameters in the Pandas read_csv() function that are useful to have in your arsenal of data science techniques:
Specifying Data Types
As mentioned before, CSV files do not contain any type information for data. Data types are inferred through examination of the top rows of the file, which can lead to errors. To manually specify the data types for different columns, the dtype parameter can be used with a dictionary of column names and data types to be applied, for example: dtype={"name": str, "age": np.int32}.
Note that for dates and date times, the format, columns, and other behaviour can be adjusted using parse_dates, date_parser, dayfirst, keep_date parameters.
Skipping and Picking Rows and Columns From File
The nrows parameter specifies how many rows from the top of CSV file to read, which is useful to take a sample of a large file without loading completely. Similarly the skiprows parameter allows you to specify rows to leave out, either at the start of the file (provide an int), or throughout the file (provide a list of row indices). Similarly, the usecols parameter can be used to specify which columns in the data to load.
Custom Missing Value Symbols
When data is exported to CSV from different systems, missing values can be specified with different tokens. The na_values parameter allows you to customise the characters that are recognised as missing values. The default values interpreted as NA/NaN are: ‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’.
# Advanced CSV loading example
data = pd.read_csv(
"data/files/complex_data_example.tsv", # relative python path to subdirectory
sep='\t' # Tab-separated value file.
quotechar="'", # single quote allowed as quote character
dtype={"salary": int}, # Parse the salary column as an integer
usecols=['name', 'birth_date', 'salary']. # Only load the three columns specified.
parse_dates=['birth_date'], # Intepret the birth_date column as a date
skiprows=10, # Skip the first 10 rows of the file
na_values=['.', '??'] # Take any '.' or '??' values as NA
)
CSV Format Advantages and Disadvantages
As with all technical decisions, storing your data in CSV format has both advantages and disadvantages. Be aware of the potential pitfalls and issues that you will encounter as you load, store, and exchange data in CSV format:
On the plus side:
- CSV format is universal and the data can be loaded by almost any software.
- CSV files are simple to understand and debug with a basic text editor
- CSV files are quick to create and load into memory before analysis.
However, the CSV format has some negative sides:
- There is no data type information stored in the text file, all typing (dates, int vs float, strings) are inferred from the data only.
- There’s no formatting or layout information storable – things like fonts, borders, column width settings from Microsoft Excel will be lost.
- File encodings can become a problem if there are non-ASCII compatible characters in text fields.
- CSV format is inefficient; numbers are stored as characters rather than binary values, which is wasteful. You will find however that your CSV data compresses well using zip compression.
As and aside, in an effort to counter some of these disadvantages, two prominent data science developers in both the R and Python ecosystems, Wes McKinney and Hadley Wickham, recently introduced the Feather Format, which aims to be a fast, simple, open, flexible and multi-platform data format that supports multiple data types natively.
Additional Reading
- Official Pandas documentation for the read_csv function.
- Python 3 Notes on file paths, working directories, and using the OS module.
- Datacamp Tutorial on loading CSV files, including some additional OS commands.
- PythonHow Loading CSV tutorial.
hello, the article is really good
i’m facing a problem while importing the csv file. when i import the csv file the data type of some columns will change and wont be the same as it was in the csv.
like numeric will be changed to object or float. as i have 100 columns i cant change each column after importing
pls suggest how to import and prevent the change of d types of coulmns
and i have some blank cells in those columns in which the data type is changing while importing
Very nice write-up!
Hello all the article is really good,
but how to export the content of variable data into another csv
Still getting error:
parserError : Error tokenizing data. C error : Expected 1 feilds in line 3, saw 37
Hello All, my csv have something like this:
“Alumina 12″ long”
Usually with quotechar = ‘ ” ‘, Pandas will ignore something within the double quotation but in my case, it will only take “Alumina 12” and skip the rest which cause troubles. How can I write the code to import with pandas?
excellent material !
Hey mate,
Appreciate the article, was a massive help! spent a few hours scouring the web for basic read_csv problem troubleshooting. Thanks again
a life saver..read lots of tutorials but they did not show how to actually load the data.thanks.
Nice solution i’ ve got from this site
Thanks for your nice article
Hi there! Thank you for your blog post! I just started using pandas and wen loading the csv file I get the following error:
TypeError: descriptor ‘axes’ for ‘BlockManager’ objects doesn’t apply to ‘SingleBlockManager’ object
I don’t understand what I am doing wrong…
Have you ever encountered this error?
Thanks and have a nice day!!
Hi there again!
I just noticed that the error came from an outdated version of Pandas.
After updating everything works fine!
Thanks, just wanted to let you know!!
I really liked how you went into detail : I truly hate reading explanations that leave out crucial information for understanding. It’s much better to be more verbose than not!! Thanks!
Great!
Hi
So plainly explained. Love the post. It simply works for me.
I was trying to import my csv file and I had a lot of errors. However, this tutorial helped me a to solve all the errors i got
Hi Juan – CSV files playing with Pandas can be a nightmare. I’m glad that the post helped you out!
Thank you so much! I had to import a CSV file and couldn’t determine the correct path until reading your material!